

In the ever-evolving landscape of artificial intelligence, OpenAI has once again pushed the boundaries with their latest offering, OpenAI.fm. This interactive playground showcases the company’s cutting-edge text-to-speech capabilities, allowing developers and curious minds alike to experiment with generating remarkably human-like voices. Let’s dive deep into what makes this platform tick, how it stacks up against competitors, and whether it’s worth incorporating into your next project.
What Is OpenAI.fm and How Does It Work?
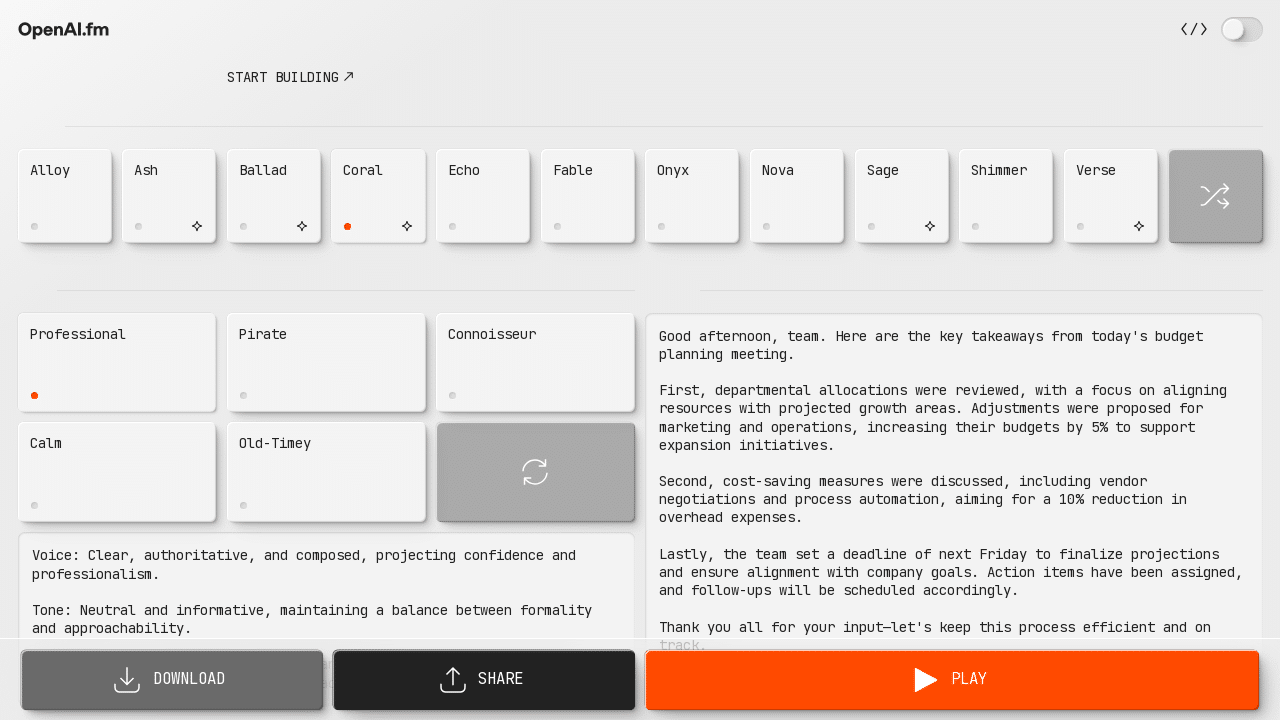
OpenAI.fm serves as an interactive demonstration platform for OpenAI’s newest text-to-speech model, gpt-4o-mini-tts. Unlike traditional text-to-speech systems that often sound robotic and monotonous, this model brings a refreshing level of naturalness to AI-generated speech. The platform allows users to select from 11 distinct voice options including Alloy, Ash, Ballad, Coral, Echo, Fable, Onyx, Nova, Sage, Shimmer, and Verse, each with its own unique characteristics and tonal qualities.
But what really sets OpenAI.fm apart is its innovative “steerability” feature. You’re not just stuck with static, pre-defined voice patterns – you can actually guide the AI to speak with specific emotions, pacing, and stylistic elements through natural language instructions. Want a voice that sounds like an enthusiastic fitness instructor? Or perhaps a soothing bedtime storyteller? OpenAI.fm can deliver both with impressive accuracy.
Technical Capabilities and Performance Analysis
Under the hood, OpenAI.fm is powered by several cutting-edge audio models. The platform showcases the gpt-4o-mini-tts model, which forms part of OpenAI’s audio lineup that also includes two speech-to-text models: gpt-4o-transcribe and gpt-4o-mini-transcribe.
The text-to-speech model outputs high-quality 48kHz audio, providing crisp, clear sound that approaches professional recording quality. It supports over 50 languages, making it a versatile option for global applications, though early user reports suggest it performs best with English content.
From a technical standpoint, the platform excels in several areas:
Voice customization flexibility: The ability to adjust parameters like voice affect and tone directly within your script offers unprecedented control over output.
Response time optimization: The lightweight model delivers audio quickly enough for interactive applications.
API integration simplicity: The platform automatically generates code snippets in Python, JavaScript, or curl, streamlining the implementation process for developers.
Emotional range versatility: The model can express a wide spectrum of emotions, from excitement to contemplation, with remarkable subtlety.
However, some users have reported audio quality issues, particularly noting artifacts at the beginning and end of generated clips. Compared to specialized competitors like ElevenLabs, some find the naturalness slightly lacking in certain contexts.
Real-World Applications for OpenAI.fm
The flexibility and quality of OpenAI.fm open doors to numerous practical applications across industries:
Content Creation and Entertainment
For content creators seeking to enhance podcasts, YouTube videos, or audiobooks without hiring voice actors, OpenAI.fm presents an affordable solution. The ability to customize voice styles means creators can maintain consistent character voices throughout narratives or develop unique vocal identities for branded content. Imagine generating different character voices for animated content or creating audio versions of written articles with minimal effort.
Accessibility Enhancement
The platform offers significant potential for improving content accessibility. Publishers can quickly convert written materials into audio formats for visually impaired users. Educational institutions might leverage this technology to create audio versions of textbooks or provide multilingual narration options for diverse student populations.
Customer Experience Innovation
Businesses looking to elevate their customer interactions could integrate OpenAI.fm’s capabilities into phone systems, chatbots, or interactive kiosks. The natural-sounding voices help reduce the “talking to a robot” feeling that often plagues automated customer service experiences. The emotional range available means these systems can respond appropriately whether delivering positive or difficult information.
Game Development Enhancement
Game developers can utilize OpenAI.fm to generate diverse NPC (non-player character) voices without extensive voice acting budgets. This allows indie developers to create richer, more immersive gaming environments with characters that sound distinct and engaging.
OpenAI.fm vs. Competing Text-to-Speech Solutions
To properly evaluate OpenAI.fm, we need to understand how it compares to other leading solutions in the text-to-speech market:
OpenAI.fm vs. ElevenLabs
ElevenLabs has gained significant attention for its remarkably natural voice synthesis. Compared to OpenAI.fm, users have noted that ElevenLabs sometimes produces more natural-sounding output with fewer audio artifacts. However, OpenAI.fm offers tighter integration with other OpenAI services and potentially simpler API implementation for developers already in the OpenAI ecosystem.
Price comparison: OpenAI’s gpt-4o-mini-tts model is priced at $0.015 per minute of generated speech, making it relatively affordable compared to some premium alternatives. ElevenLabs’ pricing varies by tier but often comes in slightly higher for comparable quality.
OpenAI.fm vs. Amazon Polly
Amazon Polly has been a staple in the text-to-speech market for years, known for its reliability and AWS integration. OpenAI.fm offers more advanced emotional expression and natural-sounding voices, while Polly excels in consistent performance and established infrastructure. For applications requiring subtle emotional nuance, OpenAI.fm has a clear advantage, while Polly might be preferred for large-scale enterprise deployments requiring predictable output.
OpenAI.fm vs. Google Text-to-Speech
Google’s offering provides strong multilingual support and integration with Google Cloud services. OpenAI.fm currently edges ahead in terms of voice customization capabilities and emotional range, though Google maintains advantages in language diversity and established reliability. For creative applications requiring voice “character,” OpenAI.fm presents compelling advantages.
Getting Started with OpenAI.fm: Implementation Guide
For developers interested in implementing OpenAI.fm capabilities, the process is refreshingly straightforward:
Create an OpenAI account: You’ll need API access through OpenAI.
Generate an API key: This authenticates your requests to the service.
Install the OpenAI SDK: Available for various programming languages including Python and JavaScript.
Make API calls: A basic Python implementation looks like:
import openai
openai.api_key = "your-api-key"
response = openai.audio.speech.create(
model="gpt-4o-mini-tts",
voice="alloy",
input="Hello, this is OpenAI's text-to-speech API."
)
response.stream_to_file("output.mp3")
The playground at OpenAI.fm also automatically generates code snippets based on your voice selections and script, making implementation even simpler for those new to the API.
Ethical Considerations and Potential Limitations
As with any powerful AI technology, OpenAI.fm raises important ethical considerations. Some users have flagged the potential for generating inappropriate content, highlighting the need for responsible implementation and content moderation.
The technology’s ability to create convincing human-like voices also raises questions about potential misuse for impersonation or deepfakes. Developers implementing this technology should consider appropriate safeguards and transparency measures.
Technical limitations include:
Occasional audio artifacts at the beginning and end of clips
Performance variations across different languages
Limited control over ultra-fine details of pronunciation
The Future of AI Voice Technology: Where OpenAI.fm Fits In
OpenAI.fm represents an important milestone in the evolution of AI voice technology, but it’s clearly just the beginning. As these models continue to improve, we can expect even more natural-sounding speech with greater emotional range and contextual awareness.
The integration possibilities with OpenAI’s other technologies present particularly exciting opportunities. Imagine combining ChatGPT’s conversational abilities with OpenAI.fm’s voice capabilities to create truly engaging AI assistants that not only say the right things but say them in exactly the right way.
For businesses considering implementation, OpenAI.fm offers a compelling balance of quality, customization, and cost-effectiveness. While specialized providers might offer marginal improvements in specific areas, the overall package and ease of integration make OpenAI.fm worthy of serious consideration for a wide range of applications.
Key Takeaways for Potential Users
If you’re considering implementing OpenAI.fm for your projects, keep these points in mind:
Strengths: Excellent voice customization, emotional range, and integration with the OpenAI ecosystem.
Challenges: Some audio artifacts reported, performance variations across languages.
Ideal use cases: Content creation, accessibility enhancements, interactive applications requiring emotional range.
Implementation complexity: Relatively low, especially for developers already familiar with OpenAI’s APIs.
Cost considerations: Competitively priced at $0.015 per minute of generated audio.
The platform’s “steerability” feature—allowing natural language instruction for voice characteristics—remains its most distinctive advantage in a crowded market. This capability enables creative applications that would be cumbersome or impossible with more rigid text-to-speech systems.
Whether you’re building the next generation of audiobooks, enhancing customer service systems, or creating accessible versions of your content, OpenAI.fm offers powerful tools that strike an impressive balance between quality, flexibility, and ease of use. As the technology continues to evolve, early adopters will be well-positioned to leverage these capabilities for increasingly sophisticated voice applications.
Frequently Asked Questions About OpenAI.fm
What is OpenAI.fm and what can it do?
OpenAI.fm is an interactive playground that showcases OpenAI’s text-to-speech capabilities through their gpt-4o-mini-tts model. It allows users to generate human-like speech in 11 different voices with the ability to customize tone, emotion, and delivery through natural language instructions. The platform supports over 50 languages and outputs high-quality 48kHz audio, making it suitable for various applications from content creation to accessibility tools.
How much does OpenAI.fm cost to use?
OpenAI’s gpt-4o-mini-tts model, which powers OpenAI.fm, is priced at $0.015 per minute of generated speech. This makes it relatively affordable compared to some premium alternatives in the market. Users pay only for the audio they generate, with no subscription fees required for basic API access. However, you will need an OpenAI account with API access to implement the service in your projects.
How does OpenAI.fm compare to ElevenLabs and other text-to-speech tools?
OpenAI.fm offers excellent voice customization and emotional range with simpler API implementation for developers already using OpenAI services. ElevenLabs sometimes produces more natural-sounding output with fewer audio artifacts but at a slightly higher price point. Compared to Amazon Polly, OpenAI.fm provides better emotional expression while Polly excels in reliability for enterprise deployments. Google Text-to-Speech has stronger multilingual support, but OpenAI.fm offers superior voice customization capabilities.
What are the 11 voice options available on OpenAI.fm?
OpenAI.fm offers 11 distinct voice options: Alloy, Ash, Ballad, Coral, Echo, Fable, Onyx, Nova, Sage, Shimmer, and Verse. Each voice has unique characteristics and tonal qualities, allowing users to select the most appropriate voice for their specific use case. The voices range in perceived gender, age, and natural delivery style.
What languages does OpenAI.fm support?
OpenAI.fm supports over 50 languages through its gpt-4o-mini-tts model. While it performs best with English content, it can generate speech in numerous languages including Spanish, French, German, Japanese, Chinese, Arabic, Hindi, Portuguese, and many others. The quality and natural cadence may vary somewhat between languages.
How do I implement OpenAI.fm in my own projects?
To implement OpenAI.fm capabilities in your projects, you need to: 1) Create an OpenAI account and generate an API key, 2) Install the OpenAI SDK for your preferred programming language (Python, JavaScript, etc.), 3) Make API calls to the text-to-speech service, and 4) Process and use the returned audio file. The OpenAI.fm playground provides auto-generated code snippets based on your voice selections and script to simplify implementation.
What is the “steerability” feature in OpenAI.fm?
The steerability feature is what makes OpenAI.fm particularly powerful. It allows users to guide the AI to speak with specific emotions, pacing, and stylistic elements through natural language instructions. For example, you can instruct the system to “speak enthusiastically like a sports announcer” or “narrate calmly like a meditation guide.” This provides unprecedented control over the output without requiring technical parameters or complex configurations.
What are the technical limitations of OpenAI.fm?
Some technical limitations of OpenAI.fm include occasional audio artifacts at the beginning and end of generated clips, performance variations across different languages (with English generally performing best), and limited control over ultra-fine details of pronunciation compared to some specialized solutions. Some users have reported that the naturalness is slightly lacking in certain contexts compared to competitors like ElevenLabs.
What are the best use cases for OpenAI.fm?
OpenAI.fm excels in several use cases: content creation (podcasts, YouTube videos, audiobooks), accessibility enhancement (converting written materials to audio for visually impaired users), customer experience innovation (phone systems, chatbots), and game development (generating diverse NPC voices). It’s particularly valuable for applications requiring emotional range and voice customization without extensive technical setup.
Are there any ethical concerns with using OpenAI.fm?
Yes, there are several ethical considerations. The technology’s ability to create convincing human-like voices raises questions about potential misuse for impersonation or creating deepfakes. Some users have flagged concerns about generating inappropriate content. Developers implementing this technology should consider appropriate safeguards, content moderation, and transparency measures to prevent misuse and maintain user trust.
How does OpenAI.fm handle voice emotion and affect?
OpenAI.fm handles voice emotion and affect through its innovative steerability feature. Users can include natural language instructions within their script to guide the emotional delivery of the generated speech. For example, adding “[speaking excitedly]” before text will cause the AI to generate speech with an excited tone. The system can express a wide range of emotions from excitement to contemplation with remarkable subtlety, making the output more engaging and contextually appropriate.
What audio quality does OpenAI.fm deliver?
OpenAI.fm’s gpt-4o-mini-tts model outputs high-quality 48kHz audio, providing crisp, clear sound that approaches professional recording quality. This makes it suitable for professional applications like podcasts, audiobooks, and commercial content. However, some users have reported audio artifacts, particularly at the beginning and end of generated clips, which may require post-processing for professional use cases.
Can OpenAI.fm create custom voices based on samples?
Currently, OpenAI.fm does not offer the ability to create custom voices based on voice samples. Users are limited to the 11 pre-defined voices provided by the platform (Alloy, Ash, Ballad, Coral, Echo, Fable, Onyx, Nova, Sage, Shimmer, and Verse). This differs from some competitors like ElevenLabs which do offer voice cloning capabilities. However, OpenAI’s steerability feature allows substantial customization of the existing voices.
How does OpenAI.fm integrate with other OpenAI products?
While OpenAI.fm primarily showcases the text-to-speech capabilities, it’s designed to integrate seamlessly with other OpenAI services. Developers can combine it with ChatGPT or GPT-4 to create conversational AI systems that not only generate appropriate textual responses but also convert them to natural-sounding speech. The unified API structure makes it relatively straightforward to incorporate voice capabilities into existing OpenAI-powered applications.
Is OpenAI.fm suitable for real-time applications?
The gpt-4o-mini-tts model that powers OpenAI.fm is designed to be lightweight and responsive enough for many interactive applications. However, the response time may not be suitable for truly real-time applications requiring instantaneous feedback (like voice chat systems with zero perceptible delay). It works best for applications where a slight processing delay is acceptable, such as generating responses for virtual assistants or creating audio content that doesn’t require instantaneous generation.
What programming languages can I use with OpenAI.fm?
OpenAI provides SDKs and support for multiple programming languages including Python, JavaScript/Node.js, and others. The platform automatically generates code snippets in Python, JavaScript, or curl, making implementation straightforward regardless of your preferred development environment. RESTful API endpoints are also available, allowing integration with virtually any programming language capable of making HTTP requests.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}